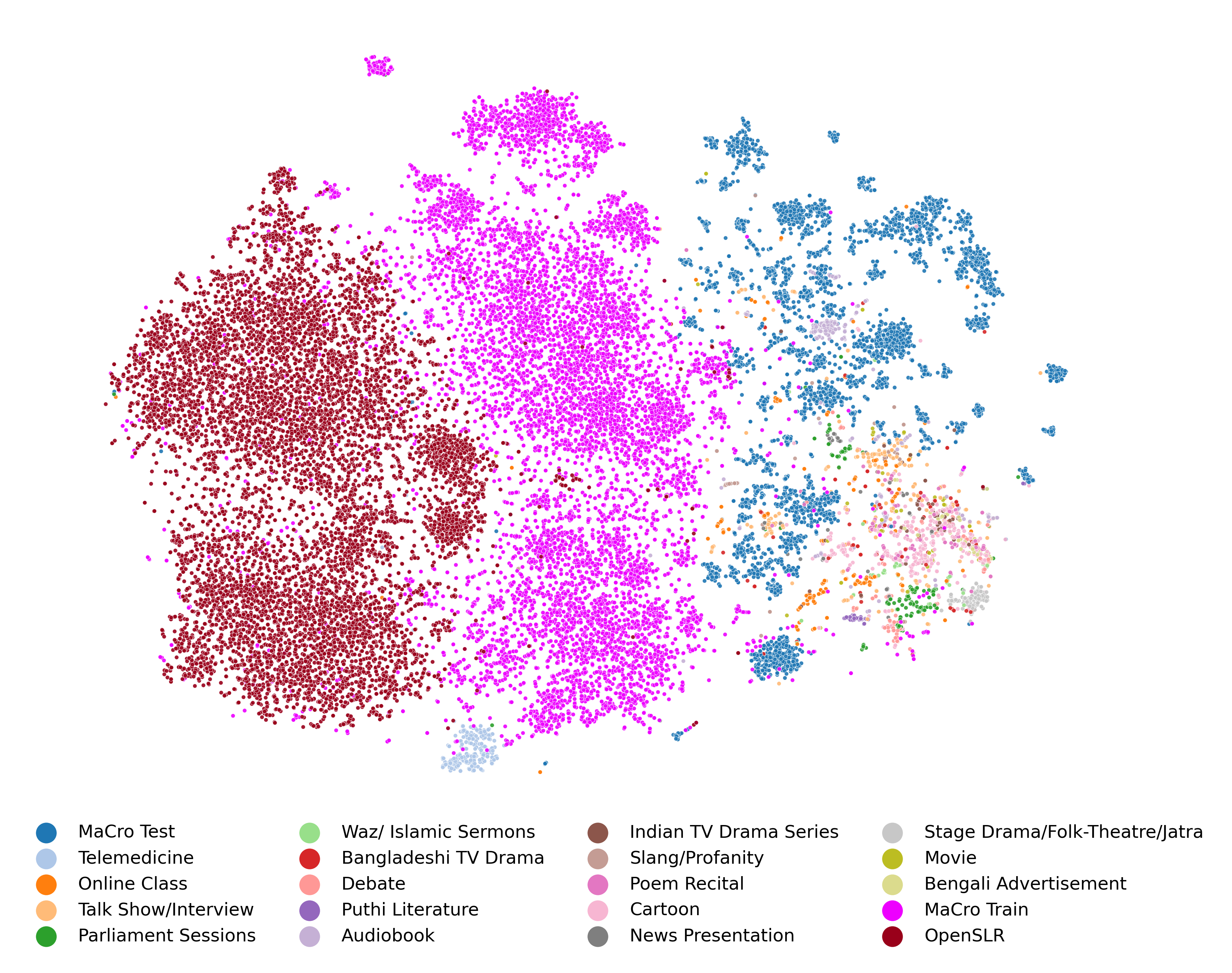
Domain shift in different domains of speech data.
OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking INTERSPEECH 2023
Abstract
We present OOD-Speech, the first out-of-distribution (OOD) benchmarking dataset for Bengali automatic speech recognition (ASR). Being one of the most spo- ken languages globally, Bengali portrays large diversity in dialects and prosodic features, which demands ASR frameworks to be robust towards distribution shifts. For example, islamic religious sermons in Bengali are deliv- ered with a tonality that is significantly different from regular speech. Our training dataset is collected via mas- sively online crowdsourcing campaigns which resulted in 1177.94 hours collected and curated from 22, 645 native Bengali speakers from South Asia. Our test dataset com- prises 23.03 hours of speech collected and manually anno- tated from 17 different sources, e.g., Bengali TV drama, Audiobook, Talk show, Online class, and Islamic sermons to name a few. OOD-Speech is jointly the largest pub- licly available speech dataset, as well as the first out-of- distribution ASR benchmarking dataset for Bengali.
Project Details
This is the largest publicly available speech recognition corpus for Bengali. The data crowdsourcing started at 21st Feb 2022 and still ongoing. The data contributors come from all walks life and the dataset has representative samples from different demographic strata and domains (gender, regional accent, age, background noise etc). The test data comprises of challanging samples from different types of scripted and spontaneous speech recordings. A Kaggle community research competition based on an earlier version of this dataset won the Kaggle Community Competition Award for the month of July, 2022. Currently a dedicated team is extending the dataset to include representative samples for the different major regional dialects of Bengali. More big news coming!! Stay tuned.
(Still Ongoing) Speech Recog. Project Contributors
Data Collection and Curation: Souhardya Saha, Fazle Rakib, Marsia Meghla, Imtiaz Prio, Rezuwan Hassan, Mayank, Siha Haque, Rezwana Sultana, Tahmid Hossain
Web Platform: Mamunur Rahman, Manash Kumar Mandal, Shakirul Islam
Modeling and Analysis: Tahsin Reasat, Nazia Tasnim, Istiak Shihab, Nazmuddoha Ansary, Syed Mobasshir Hossen, Shahrin Nakkhatra, Zaowad Rahabin, Arijit Mukherjee
Linguists: Tanveer Azmal, Sazia Mehnaz, Kanij Fatema