|
Bengali.AI
A community research initiative working towards democratizing AI research for Bengali by crowdsourcing datasets and launching research competitions.
A research community of 7000+ researchers from around the world. Striving towards the same goal: Development of language tech of Bengali. Bangla/Bengali (বাংলা) has a rich heritage of literature that dates back to almost a thousand years. Even with a huge number of native speakers, Bengali is lagging behind in language tech due to lack of curated large datasets.
From government services to education, from agriculture to healthcare, Bengali language tech research would make lives easier for everyone.
Email /
Twitter /
Github /
Community Group /
Facebook
|

|
|
Research
We are currently more interested in computer vision, speech and NLP based research. In parallel our teams work on Linguistic theory, language documentation, meme research and much more!
|
|
|
OOD-Speech: Bengali.AI Massively Crowdsourced Bengali Speech Recognition Project
INTERSPEECH, 2023
Kaggle Featured Competition
/
Project Page
/
Paper
Jointly largest open-sourced Bengali ASR dataset as well as first Bengali Out-of-Distribution Speech Recognition benchmarking dataset. 25,000+ people contributed in the development of this dataset.
|
|
|
BaDLAD: A Large Multi-Domain Bengali Document Layout Analysis Dataset
ICDAR, 2023
project page
/
Paper
The first multidomain large Bengali Document Layout Analysis Dataset: BaDLAD.
This dataset contains 33,695 human annotated document samples from six domains - i) books and magazines ii) public domain govt. documents
iii) liberation war documents iv) new newspapers v) historical newspapers and vi) property deeds. 700K polygon annotations from image captured documents in the wild.
|
|
|
bbOCR: An Open-source Multi-domain OCR Pipeline for Bengali Documents
Arxiv, 2023
Project Page
/
Paper
The first Opensourced complete OCR pipeline for Bengali. We provide 2 synthetic datasets for word recognition and one hand annotated complete document deconstruction dataset BCD3 with 228 domain diversified samples. We benchmark our models on the BCD3 dataset and opensource the datasets and the models+system for further research. We will keep updating the dataset.
|
|
|
Bengali Grammatical Error Correction Project
arXiv, 2023
Project Page
/
Kaggle Competition
Large Bengali grammatical error detection and correction project. Involves a novel linguist validated dataset with 100k+ sentence samples with word-level anntoatation. Hosted a Kaggle competition in 2023 to crowdsource solutions.
|
|
|
bornil: An open-source, sign language data crowdsourcing platform for AI enabled dialect-agnostic communication and domain study.
Arxiv, 2023
Project Page
/
Paper
The first opensourced and publicly available sign language data collection tool. The commonvoice for sign languages.
|
|
|
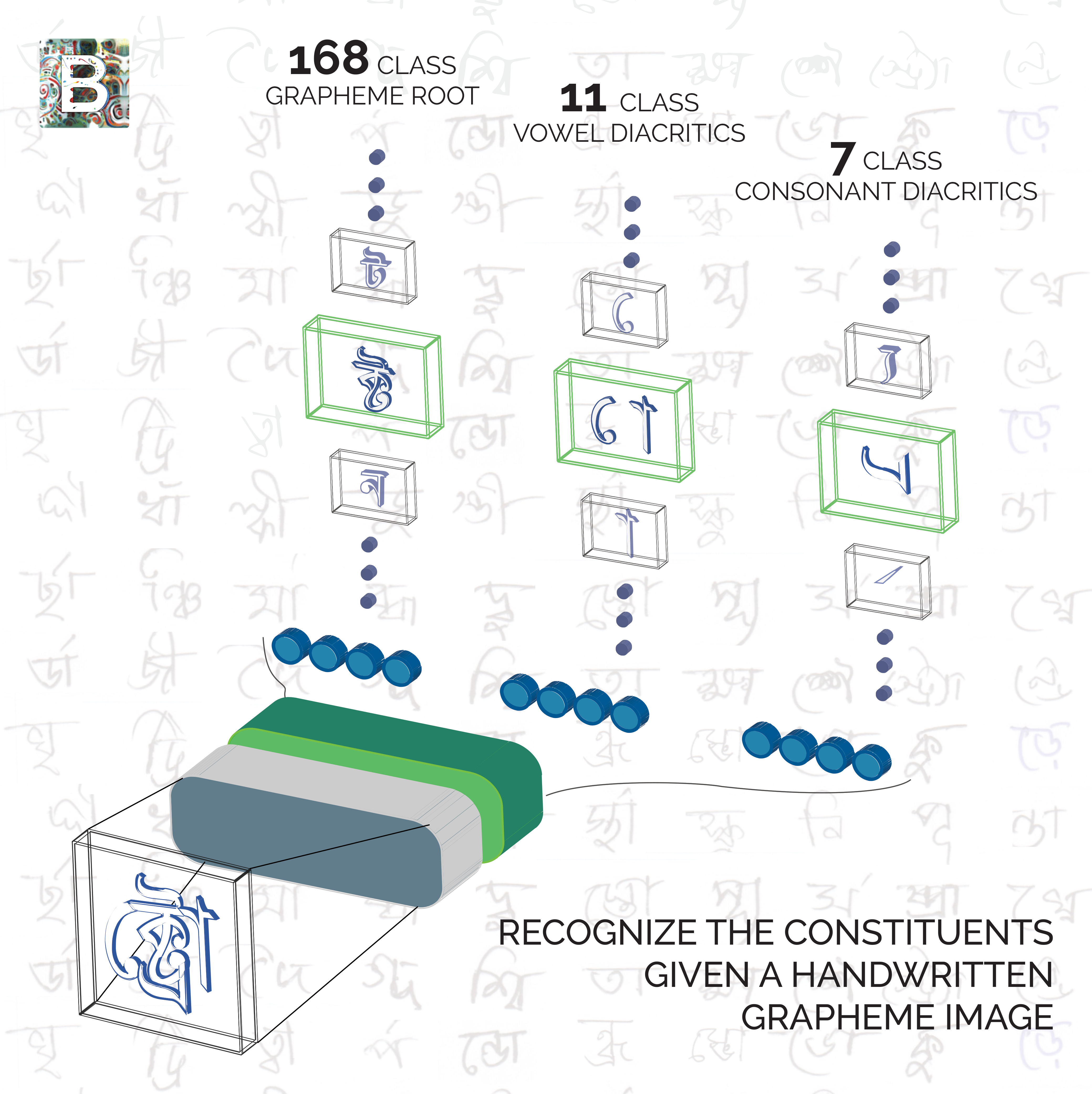
A Large Multi-Target Dataset of Common Bengali Handwritten Graphemes
ICDAR, 2021
Kaggle Featured Competition
/
Paper
A benchmark datset for multi-target classification of handwritten Bengali Graphemes, with novel implications for all alpha-syllabary languages, e.g., Hindi, Gujrati, and Thai.
|
|
|
The first large scale Multi-Domain Bengali Handwritten Digit Recognition Dataset
Arxiv, 2018
Kaggle Competition
/
Paper
The first large scale Multi-Domain Bengali Handwritten Digit Recognition Dataset.
|
|
Competitions
Bengali.AI regularly launches research competitions in collaboration with industry, academia and government collaborators. Currently, a $53,000 Kaggle featured competition is ongoing on Bengali Automatic Speech Recognition. To know more about the competitions, visit the Competitions Page.
|
|